Data Anonymization vs. Data Pseudonymization: Sự khác biệt là gì? So sánh hai kỹ thuật bảo mật dữ liệu và ứng dụng của chúng

Trong thời đại số hóa hiện nay, việc bảo vệ dữ liệu cá nhân và thông tin nhạy cảm trở thành một trong những nhiệm vụ quan trọng hàng đầu. Hai kỹ thuật phổ biến trong bảo mật dữ liệu là anonymization (ẩn danh) và pseudonymization (mã hóa giả). Tuy cả hai đều nhằm mục tiêu bảo vệ thông tin cá nhân, nhưng chúng có những điểm khác biệt rõ rệt về quy trình và ứng dụng. Bài viết này sẽ so sánh hai kỹ thuật này và làm rõ sự khác biệt giữa chúng.
Khái niệm về Anonymization và Pseudonymization
Anonymization (Ẩn danh)
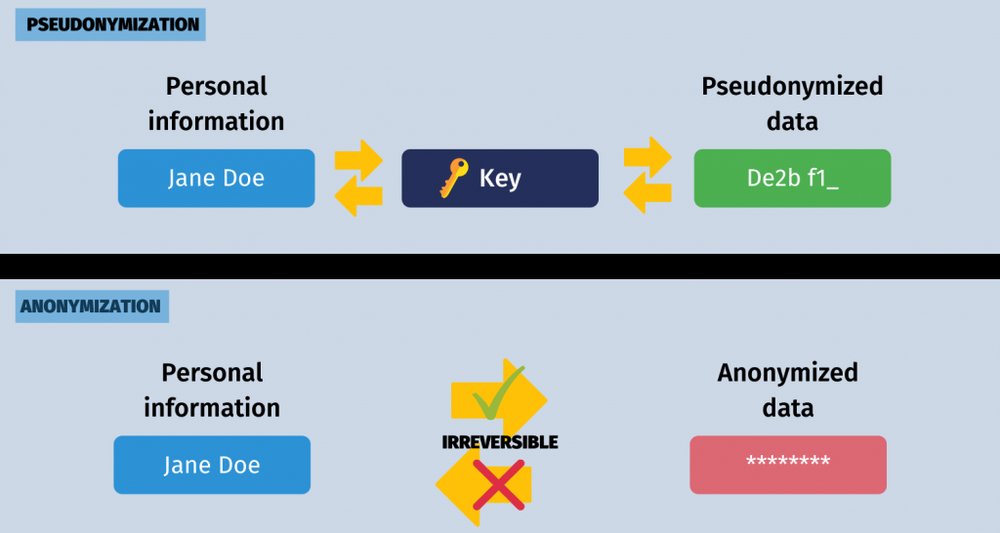
Anonymization là quá trình loại bỏ hoặc làm biến đổi thông tin nhận dạng từ một tập dữ liệu, để các cá nhân không thể được xác định. Dữ liệu sau khi được ẩn danh không thể được khôi phục để tái tạo thông tin cá nhân, nghĩa là thông tin đó không còn là thông tin nhạy cảm.
Ví dụ: Khi chúng ta thay đổi tên của một khách hàng thành "Khách hàng 1", mọi thông tin liên quan từ địa chỉ, số điện thoại, hay các chỉ số khác cũng sẽ được xóa hoặc mã hóa để tránh khả năng nhận diện.
Pseudonymization (Mã hóa giả)
Ngược lại, pseudonymization vẫn giữ nguyên dữ liệu cơ bản nhưng thay thế các thông tin nhận diện bằng các mã giả. Dữ liệu này có thể được khôi phục lại nếu cần thiết, bằng cách sử dụng một "chìa khóa" để chuyển đổi mã giả trở lại thông tin gốc.
Ví dụ: Nếu tên của khách hàng được lưu dưới dạng mã số duy nhất, như "KH123", thông tin này là mã hóa giả, và tổ chức có thể khôi phục lại danh tính của người đó nếu họ có chìa khóa tương ứng.
So sánh Anonymization và Pseudonymization
| Tiêu chí | Ẩn danh (Anonymization) | Mã hóa giả (Pseudonymization) | |---------------------|--------------------------------------|------------------------------------| | Tính khôi phục | Không thể khôi phục thông tin gốc | Có thể khôi phục thông tin gốc | | Mức độ bảo vệ | Cao hơn, khó nhận diện | Thấp hơn, phụ thuộc vào chìa khóa | | Ứng dụng | Nghiên cứu, phân tích dữ liệu lớn | Duy trì khả năng xác định danh tính | | Xử lý dữ liệu | Phức tạp hơn do cần loại bỏ thông tin | Dễ dàng hơn, vẫn giữ thông tin gốc | | Quy định pháp lý | Phù hợp với nhiều quy định bảo mật | Cần tuân thủ quy định bảo vệ dữ liệu |
Ứng dụng của Anonymization và Pseudonymization
1. Ứng dụng của Anonymization
Anonymization thường được sử dụng trong các lĩnh vực như:
-
Nghiên cứu y tế: Khi nghiên cứu thông tin về bệnh nhân, các nhà nghiên cứu cần dữ liệu để phân tích nhưng không cần thông tin cá nhân cụ thể.
-
Phân tích dữ liệu lớn: Dữ liệu ẩn danh giúp tổ chức có thể rút ra thông tin quý giá mà không vi phạm quyền riêng tư cá nhân.
-
Chia sẻ dữ liệu: Các tổ chức có thể chia sẻ dữ liệu ẩn danh giữa các bên mà không cần lo lắng về vấn đề bảo mật.

2. Ứng dụng của Pseudonymization
Pseudonymization được ủng hộ trong những tình huống sau:
-
Quản lý dữ liệu khách hàng: Các tổ chức có thể quản lý danh tính khách hàng mà không tiết lộ thông tin cá nhân.
-
Bảo vệ quyền riêng tư trong nghiên cứu: Tạo ra mã giả cho đối tượng nghiên cứu giúp bảo vệ danh tính của họ trong khi vẫn cho phép phân tích dữ liệu.
-
Tuân thủ quy định bảo vệ dữ liệu: Pseudonymization là một cách hiệu quả để tuân thủ các quy định như GDPR mà vẫn duy trì tính khả dụng của dữ liệu.

Đánh giá các yếu tố ảnh hưởng đến việc lựa chọn kỹ thuật
Khi lựa chọn giữa ẩn danh và mã hóa giả, các yếu tố sau đây cần được xem xét:
1. Mục đích sử dụng dữ liệu
Nếu dữ liệu chỉ được sử dụng cho mục đích phân tích tổng hợp mà không cần truy ngược lại thông tin cá nhân, ẩn danh sẽ là lựa chọn hợp lý. Ngược lại, nếu cần truy cập lại thông tin gốc (ví dụ trong trường hợp có khiếu nại hoặc cần chăm sóc khách hàng), mã hóa giả sẽ phù hợp hơn.
2. Quy định pháp lý
Các quy định pháp lý khác nhau ở mỗi quốc gia có thể yêu cầu các tổ chức sử dụng một trong hai kỹ thuật. GDPR, ví dụ, khuyến khích sử dụng mã hóa giả nhưng cũng đề cao sự cần thiết của việc ẩn danh dữ liệu.
3. Tính khả thi kỹ thuật
Việc thực hiện ẩn danh có thể phức tạp hơn và yêu cầu các công cụ và kỹ thuật tiên tiến hơn so với mã hóa giả. Do đó, các tổ chức cần xem xét khả năng và nguồn lực để thực hiện các kỹ thuật bảo vệ dữ liệu này.

Kết luận
Cả anonymization và pseudonymization đều là những kỹ thuật quan trọng trong việc bảo vệ dữ liệu cá nhân trong thời đại số hóa hiện nay. Mỗi kỹ thuật đều có những ưu điểm và hạn chế riêng, do đó, việc lựa chọn giữa hai kỹ thuật này tùy thuộc vào ngữ cảnh, mục đích sử dụng dữ liệu cũng như các quy định pháp lý hiện hành.
Sử dụng đúng kỹ thuật có thể giúp tổ chức bảo vệ quyền riêng tư của người dùng, đồng thời cũng duy trì được giá trị sử dụng của dữ liệu. Hy vọng rằng bài viết này sẽ giúp các bạn có cái nhìn rõ ràng hơn về sự khác biệt giữa ẩn danh và mã hóa giả, cũng như ứng dụng của chúng trong thực tiễn.

Có thể bạn quan tâm

Data Science có thể giúp bạn ra quyết định chiến lược như thế nào? Ứng dụng trong doanh nghiệp, các công cụ cần thiết, và lợi ích dài hạn
Biểu đồ dạng bánh kép trong Looker Studio: Cách trình bày dữ liệu phân đoạn và tối ưu hóa biểu đồ
Google Sheets nâng cao có thể giúp quản lý tài liệu tốt hơn không? Các công cụ tích hợp, ứng dụng trong doanh nghiệp, và mẹo sử dụng
Google Sheets nâng cao có thể giúp quản lý thời gian hiệu quả hơn không? Các tính năng đặc biệt, ứng dụng trong quản lý, và mẹo sử dụng
Generative AI có thể tạo ra nội dung sáng tạo như thế nào? 50 công cụ hàng đầu, ứng dụng thực tế, và lợi ích dài hạn
Tự động hóa quy trình kinh doanh với Coze AI có lợi ích gì? Các trường hợp thành công, phân tích chi phí, và cách bắt đầu
Federated Learning là gì? Giải thích thuật ngữ, cách hoạt động, và ứng dụng trong bảo mật dữ liệu
Google Sheets nâng cao có thể giúp quản lý nhóm như thế nào? Các công cụ tích hợp, ứng dụng trong làm việc nhóm, và mẹo sử dụng
Looker Studio khác gì với PowerBI? So sánh chi tiết, ứng dụng cho doanh nghiệp, và trường hợp sử dụng thực tế
Clustering là gì trong Machine Learning? Giới thiệu các thuật ngữ, cách hoạt động, và ví dụ ứng dụng thực tế
Ensemble Learning Techniques là gì? Tìm hiểu về các kỹ thuật học tập kết hợp, cách hoạt động, và lợi ích cho mô hình AI




